- Published on
Understanding Bitcask - Log structured hash indexed KV store
- Authors

- Name
- Prithvi Anand
TLDR;
Bitcask is fast Key-Value store that takes benefits of the below two principles to serve production grade throughput in sub-millisecond times.
- Log structured file system (LFS) write data sequentially to the disk to avoid random seeks & achieve fast writes.
- Hash index is an index built over data stored on disk. It stores the location and size of data against a key. It helps achieve fast lookups.
Bitcask solves following use cases well:
- Handle datasets larger than RAM sizes w/o degradation
- Provide Low latency + High throughput on I/O operations
- Allow quick crash recovery without any loss of data
Range queries on keys require an iteration over the KeyDir and is thus non performant in Bitcask.
Hash Index
While storing data on disk, an index may be useful to quickly find it.
One simple approach to build an index is to use a map like data structure to store the starting location, size of a data block on disk (value) against an identifier (key)
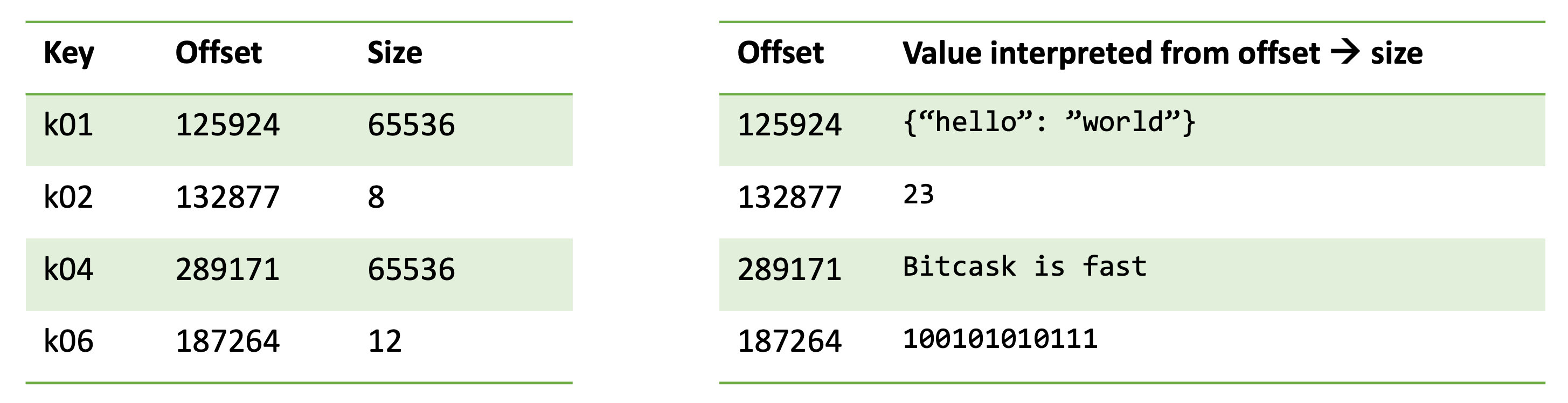
A key-value store is one simple hash index implementation, there can be used to implement more complex indexes as well.
Log Structured File System (LFS)
Log-structured File Systems (LFS) are file systems that writes data in an append-only manner, treating the disk as a circular log. The writes to an LFS are thus sequential in nature.
Sequential I/O operations don't require random seeks on the disks and are highly performant.
All data write operations (create & update) to an LFS, include new data block being written out-of-place to the disk.

Since updates to a file are written as new files, stale data is generated. This is garbage collected at intervals (also in a sequential manner) to cleanup the disk.
Additional metadata is added to each data block for correctness of data and to ensure latest data is fetched during reads.
Bitcask
Bitcask is an implementation that draws inspiration from LFS and builds a Hash Index on top of it to achieve fast read, write operations. It was built to develop Riak, a distributed key value store which stores values on disk.
Design
File Structure
Bitcask stores a KV pair as a file on the disk. Each file has a key and a value block.
Additionally, it stores meta information for key_size, value_size, timestamp & crc.
While reading data sequentially, the sizes help identify the number of bytes to be read to identify a key/value.
CRC (cyclic redundancy check) is a hash stored against each file to ensure correctness of data. Timestamp is used for
internal use and not exposed.
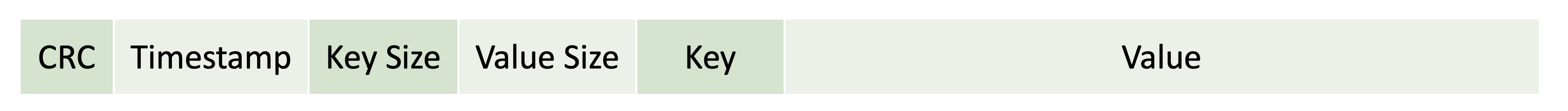
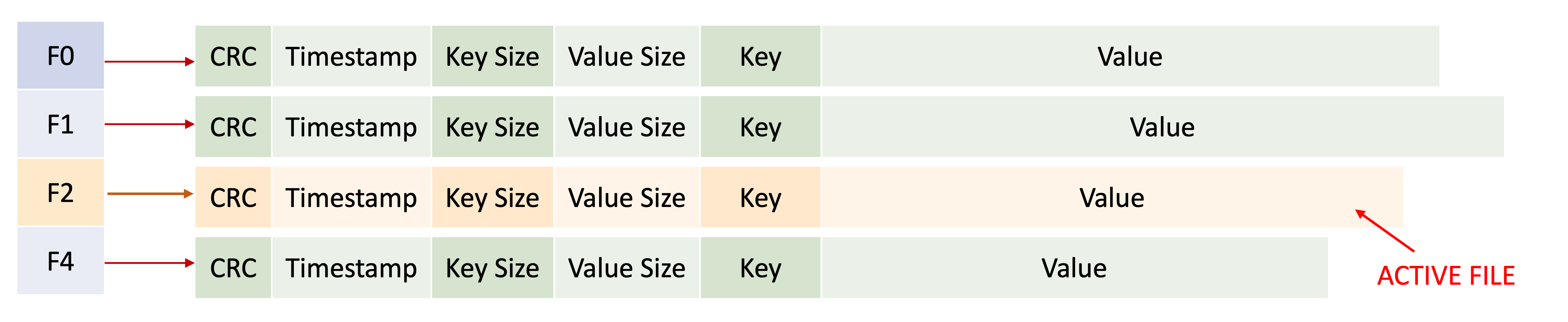
A bitcask instance stores multiple files. To perform a write operation to a file, it is marked as active. By design, only one file is allowed to be active at a time. However, other files continue to be available for reads.
KeyDir
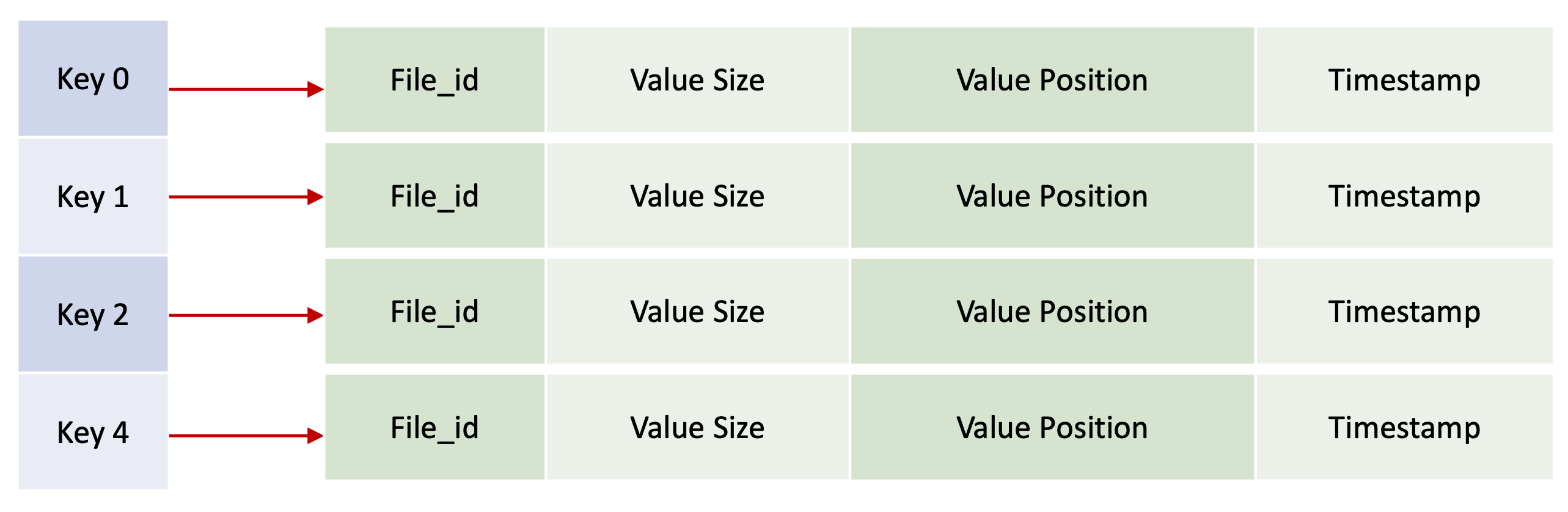
KeyDir is an in-memory map that stores the keys against the offset on the disk where the corresponding value is stored.
The value in mapped a structure that stores file_id, value_position, value_size and timestamp
CRUD Operations
Create
Following operations are executed atomically:
- New file structure is created with key, value and written to disk (sequentially at the end)
- New record is created in KeyDir with key and corresponding value position and size on disk
Read
- Given key is looked up in the KeyDir to obtain the value pos and value size
- Reader head is seeked to the value pos on disk and corresponding data is obtained
- Bitcask relies on OS level cache and doesn't implement any caching of it own during reads
Update
- Similar to create operation, updated file is created and appended to the end of disk as a new record
- However, value position and size is updated against the same key in KeyDir to new values
- This leaves old file on the disk dangling without any pointers to it in KeyDir
- In the successive cleanup interval, the old version garbage collected from the disk
Delete
- Deletes are considered as updates with a tombstone value (usually a constant that may not collide with other values)
- These are also garbage collected in the successive cleanup interval
Merging old files
During the update and delete operations, files are left dangling without any references to them. This model can lead to
extensive usage of disk over time. Bitcask performs merge operation to free up this space.
During merging, all the inactive files are iterated over and only the latest versions of a file are retained.
Warming up hash index
Since KeyDir is stored in memory, it requires map to be built up every time an instance is restarted.
The value can be updated in KeyDir as online operation during the transaction, but this would require multiple random seeks which defies the core purpose of LFS storage.
Another alternative is to prepare the KeyDir by iterating over the disk once on instance boot up. This is also a heavy operation and slows down the boot time.
Bitcask optimizes this problem by storing a snapshot of KeyDir while performing merge operation on disk. This is stored
in a structure called hint_file. On successive boot up, hint file is loaded from the disk to re-create the KeyDir
This doesn't consume large size as hint file does not contain any values.
Partially written records
The instance may crash at any time, including halfway through appending a record to the log. The crc field stored in
the files allowing such corrupted parts of the log to be detected and ignored.
Concurrency control
- Writes are done at the end of disk in a sequential manner. Bitcask uses only one writer thread.
- Reads can be done only on inactive files, so they can be read concurrently by multiple threads.
Strengths
- Ability to handle datasets larger than RAM sizes w/o degradation
- Low latency + High throughput read and write operations
- Crash recovery happens quickly without any loss of data
Weakness
- The number of records is limited to size of KeyDir. In case RAM is exhausted, successive writes will start failing. However, this can solved for by vertical (increase RAM) or horizontal scaling (sharding on the keys).
- Range queries cannot be performed optimally as each key requires separate lookup in KeyDir