- Published on
LSM trees based indexing - LevelDB, Cassandra, HBase
- Authors

- Name
- Prithvi Anand
TLDR;
Problem: Hash-indexed file systems lack support to perform multi-key comparisons.
Solution: LSM Trees solve this by ordering keys on disk.
SSTable
- Disk is logically broken down to segments, each segment stores few files.
- The files in a segment are sorted by their key
- The segments are regularly compacted and merged for efficiency.
MemTable
An in-memory structure which sorts a segment before flushing to disk.
Write Process
Writes go to MemTable, flushed to disk as SSTable when MemTable is full.
Read Process
Lookup in following order: MemTable > recent on-disk segment > older on-disk segments
Introduction
Databases with hash indexes allow fast I/O, but don't allow queries involving comparisons on two or more keys. eg: Looking up files with a key starting with "ma" would require a traversal of complete hash index
Sorted String Table (SS Table)
SS Tables solve the above problem by ordering the files written on disk by keys. Following example explains the working of an SS Table:
Example
Consider following key value map stores the number of products in a warehouse (on an LFS system).
{"chair": 23, "bag": 34, "table": 12, "mat": 44, "pen": 29}
As products are added or removed, their count may be updated on the disk
Since an LFS system is an append only log, all the updates will be written out of space on the disk. Thus there may be multiple files for a product as shown below:
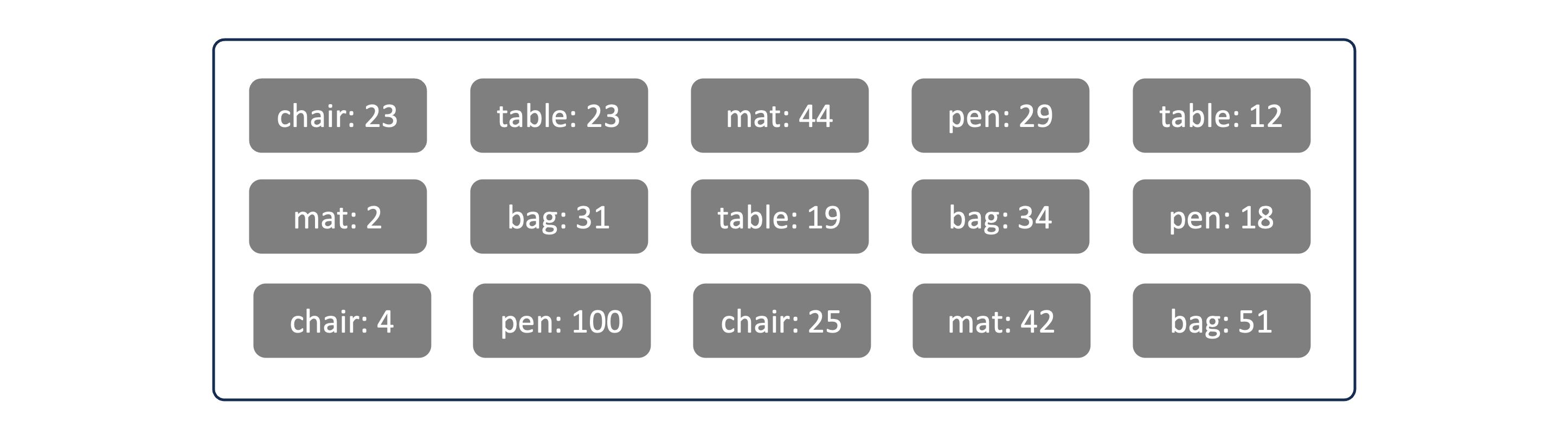
Implementation
- For implementation of an SSTable, the stored files are first organised in fixed size blocks called segments.
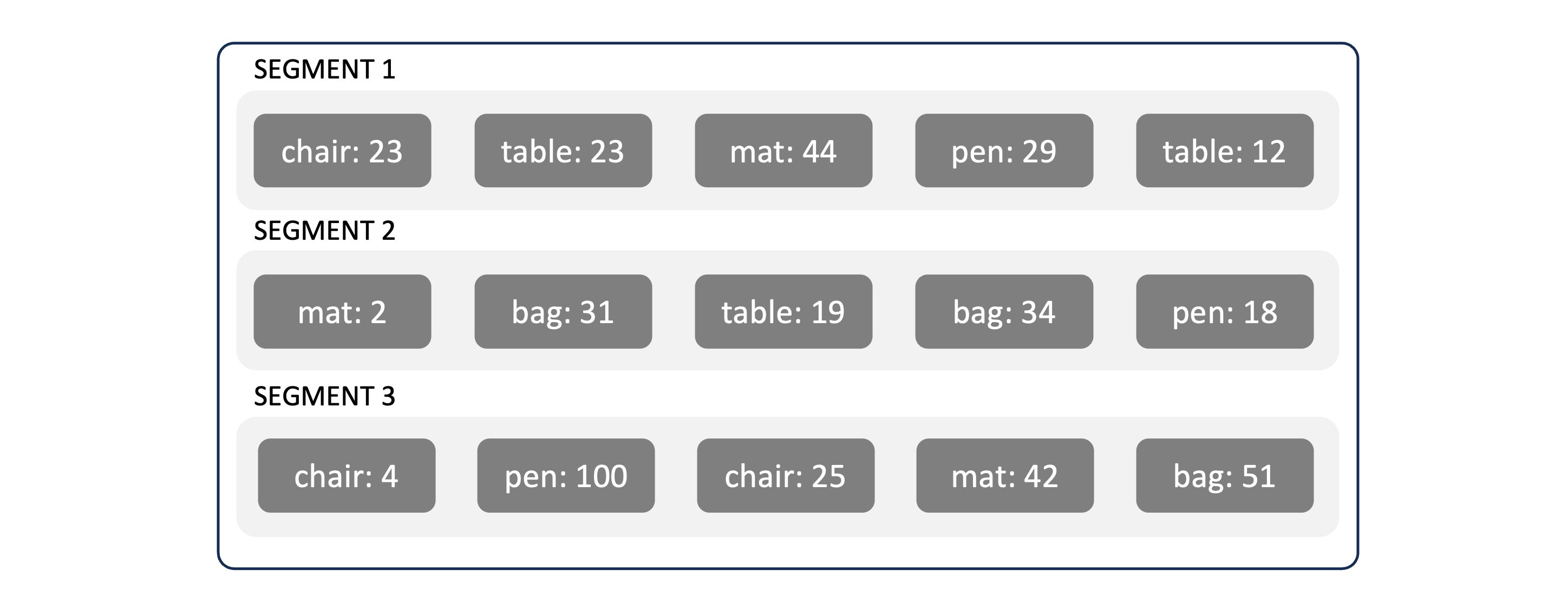
-
To implement ordering, files are sorted within a segment by the key. This is done optimally without doing random seeks using an additional in-memory data structure called MemTable. (discussed later)
-
Each segment may contain multiple files against a key. At regular intervals, these are parsed to retain the latest value only. This process is called
Compaction

- Even after compaction, there may be files across segments with same keys. The compacted outputs are then iterated to
retain latest values via process called
Merging. This operation is similar to merge sort where we merge 2 sorted arrays.
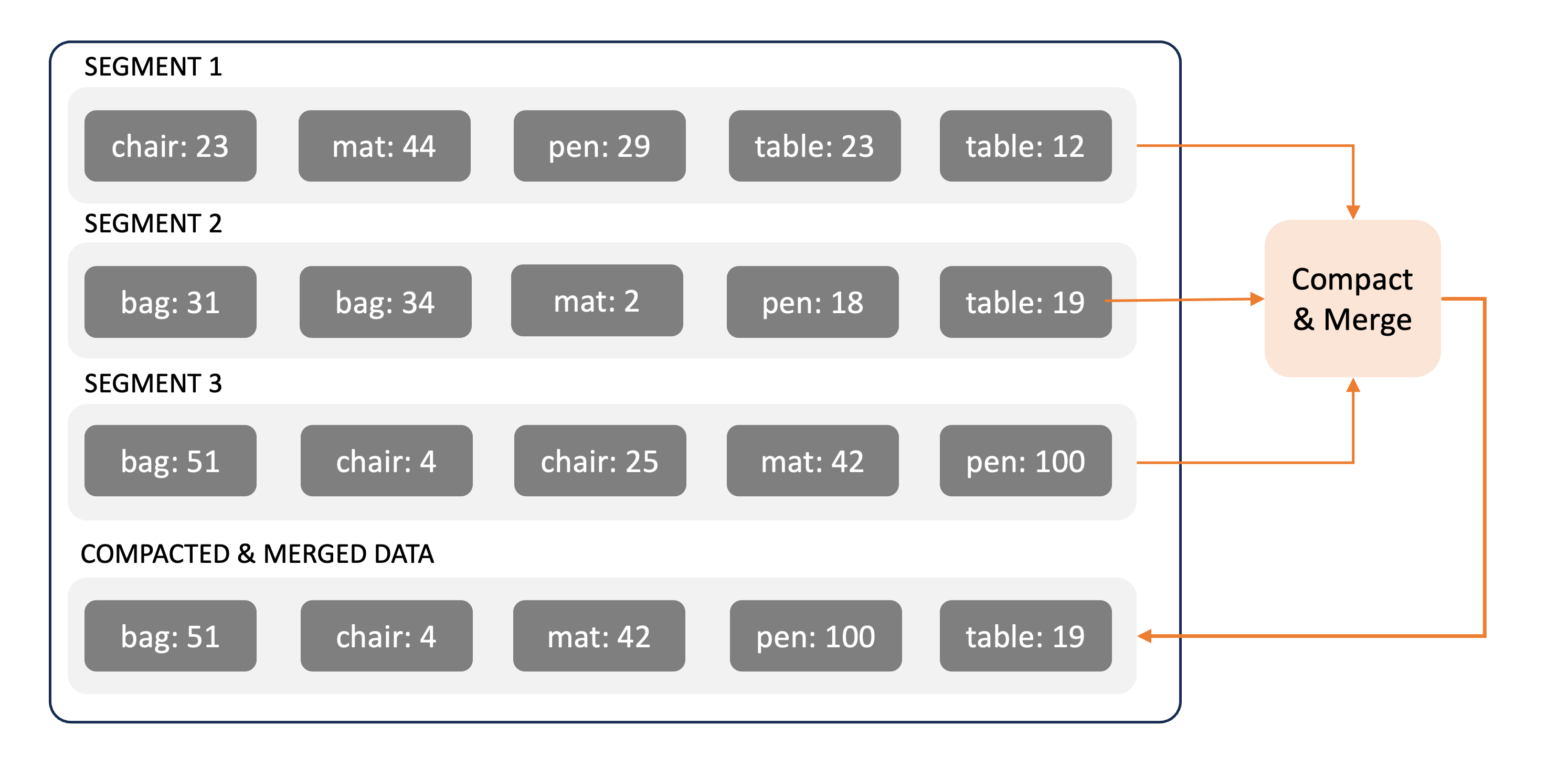
- To optimize lookup on an SSTable, a hash index is built in memory storing the key and offset on disk. This map does not require all keys to be stored, it can be made sparse since keys are written in a sorted order. In case a key is not found in the map, the previous and next keys (in sorted order) found in the map can be used to fetch pointers to block on disk in which the key can be found.
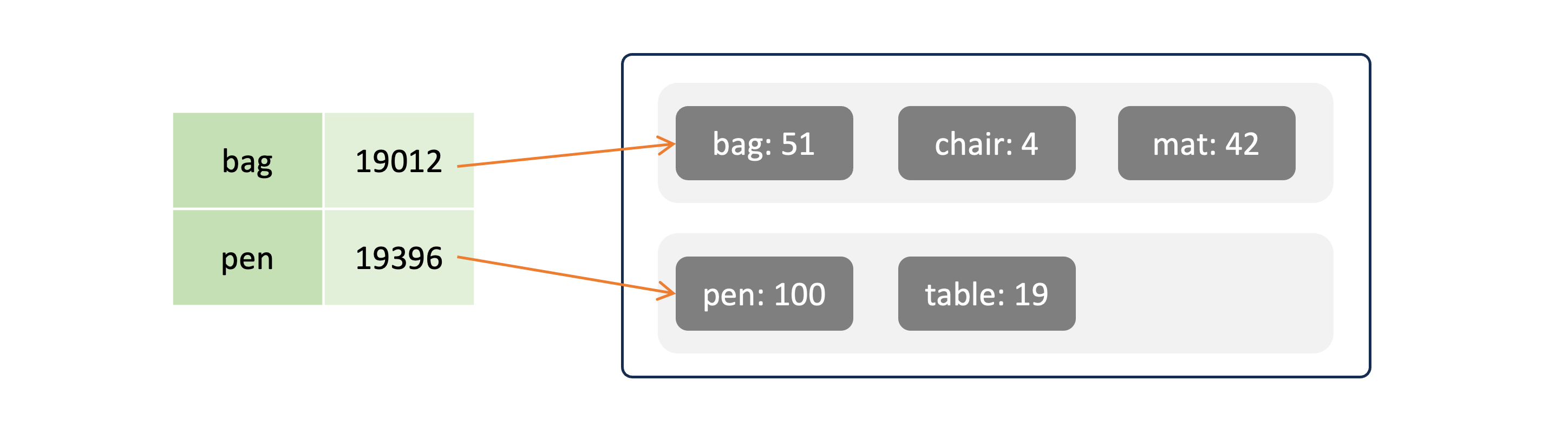
MemTable
MemTable is the data structure responsible for building the segments in a sorted order. This is usually done in memory (to avoid seeks, reads & writes on disk). Once a segment is built in memory, it is flushed to disk
The choice of data structure to build a sorted segment varies across implementations but is usually one of the many known tree structures like red black tree or AVL tree.
Bringing all the elements together
When following elements are brought together:
- Underlying file system is Log Structured file system
- SSTables make use of Merging & Compaction.
- MemTable makes use of Tree based data structure
A functional index is created. This is called Log-Structured Merge Tree
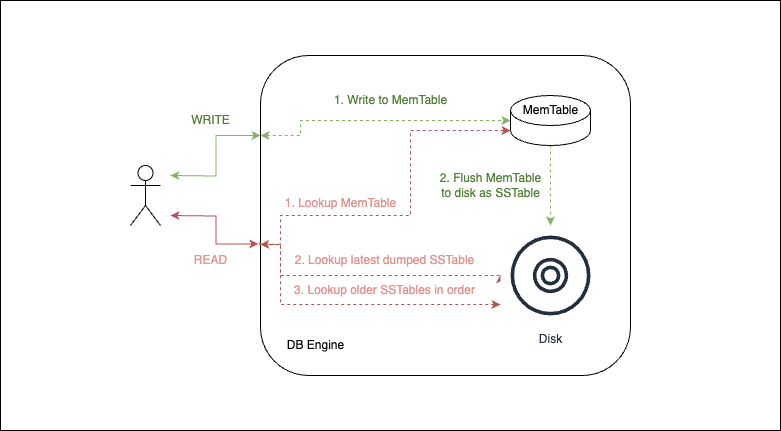
Write Operation
- When a write comes in, add it to MemTable.
- When the memtable grows beyond a threshold (~ few megabytes), dump it to disk as an SSTable.
- This SSTable file becomes the most recent segment of the database.
- While the MemTable is dumped to disk as an SSTable, writes continue to a new MemTable instance
Read Operation
In order to serve a read request, the database tries lookup in the following order:
- Try to find the key in the MemTable, where the most recent writes are stored
- If the key is not found in the MemTable, look in the most recent on-disk segment
- Progressively search in the next-older segments on disk if necessary
The LSM tree algorithm is used by multiple databases like LevelDB, RocksDb, HBase and Cassandra
Optimization for non existent keys
The LSM-tree algorithm can be slow when searching for keys that do not exist in the database. To confirm the absence of a key, we need to check the MemTable and potentially traverse all the way back to the oldest segments. This might require disk reads for each one. To optimize this type of access, storage engines often use additional Bloom filters.